A Python tool to work with any format for annotating animal sounds and bioacoustics data.
crowsetta provides a Pythonic way to work with annotation formats for animal sounds and bioacoustics data. Files in these formats are created by applications that enable users to annotate audio and/or spectrograms. Such annotations typically include the times when sound events start and stop, and labels that assign each sound to some set of classes chosen by the annotator. crowsetta has built-in support for many widely used formats such as Audacity label tracks, Praat .TextGrid files, and Raven .txt files. The images below show examples of the two families of annotation formats built into crowsetta, sequence-like formats and bounding box-like formats.
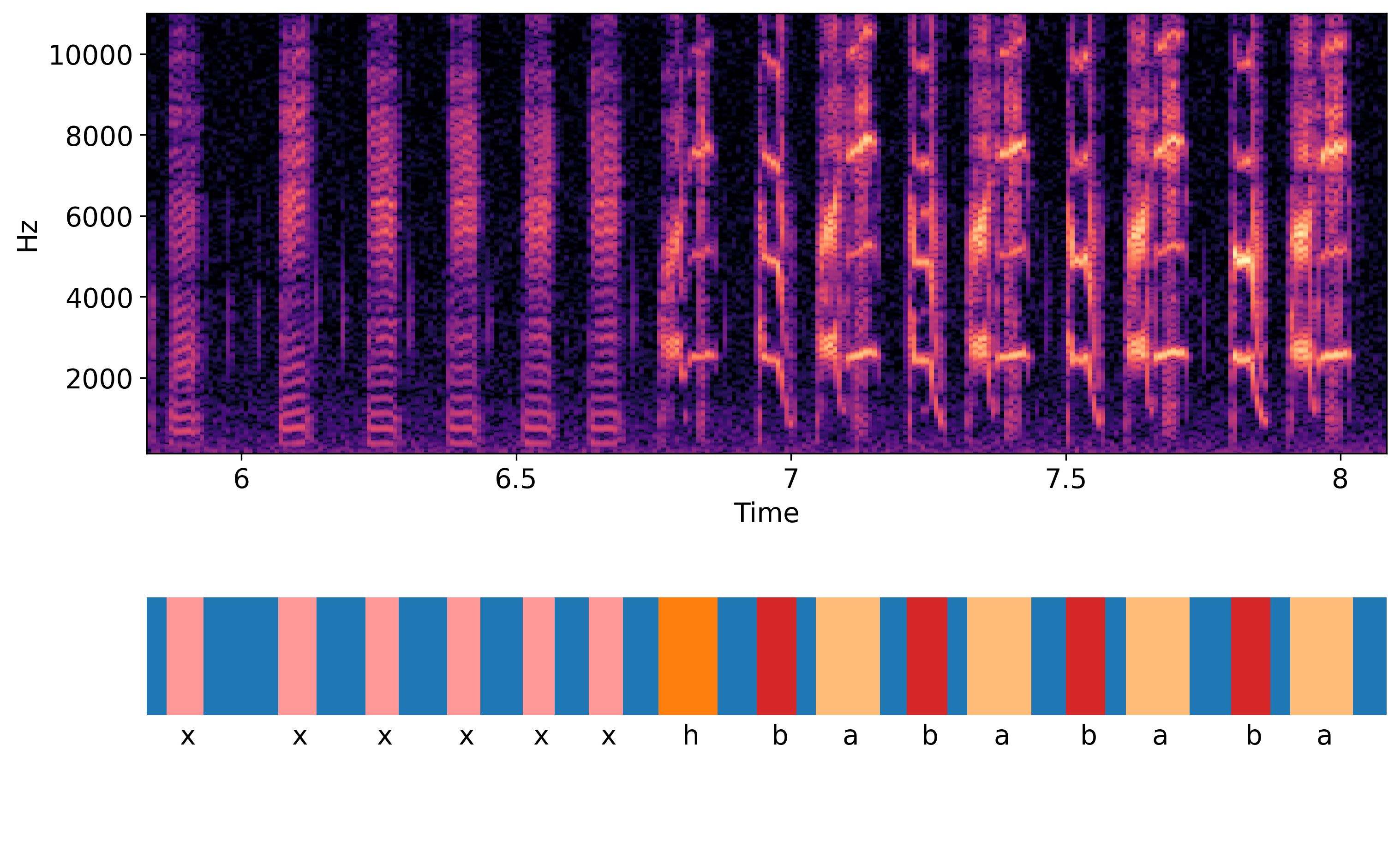
Spectrogram of the song of a Bengalese finch with syllables annotated as segments underneath. Annotations parsed by crowsetta from a file in the Praat TextGrid format. Example song from Bengalese finch song dataset, Tachibana and Morita 2021, adapted under CC-By-4.0 License.#
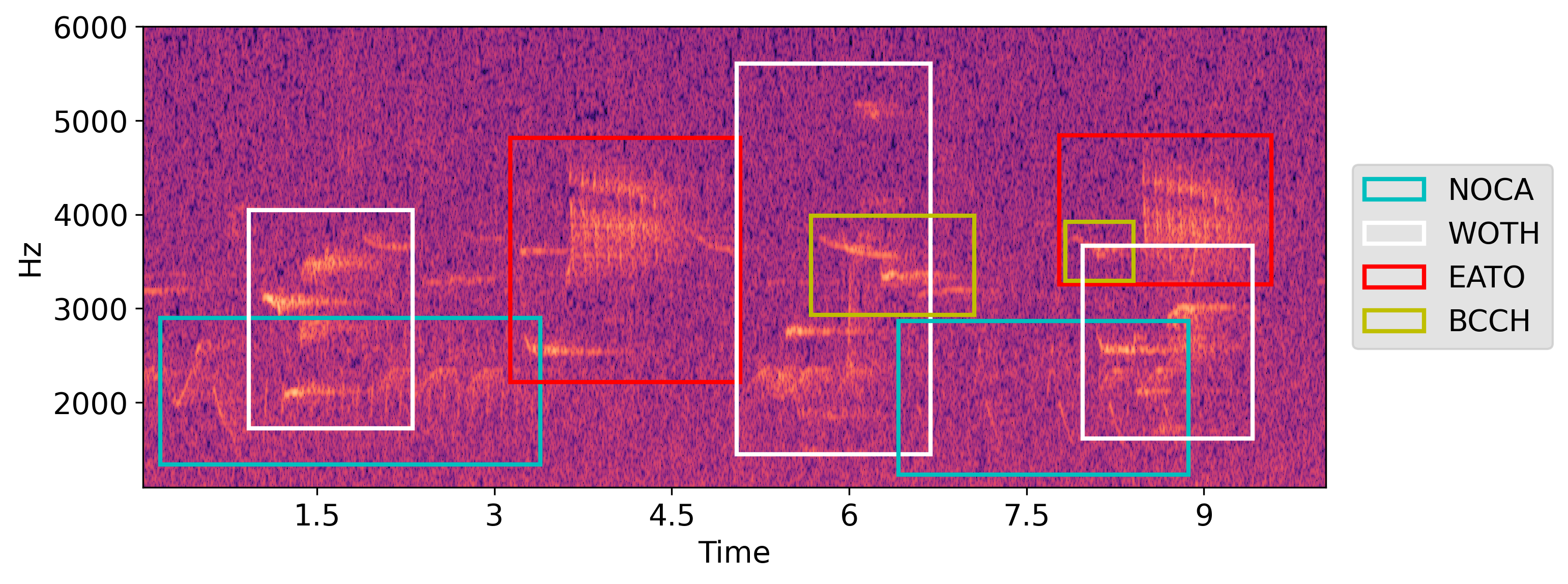
Spectrogram of a field recording with annotations of songs of different bird species indicated as bounding boxes. Annotations parsed by crowsetta from a file in the Raven Selection Table format. Example song from “An annotated set of audio recordings of Eastern North American birds containing frequency, time, and species information”, Chronister et al., 2021, adapted under CC0 1.0 License.#
About#
What can you do with crowsetta?
Analyze your annotations with Python scripts
Develop Python libraries that can work with a wide array of annotation formats
Convert your annotations to a file format that’s easy for you to share and for anyone to load, like a single csv file
Convert your annotations into a format that’s needed to train machine learning models
Who would want to use crowsetta?
Anyone that works with animal sounds or other bioacoustics data that is annotated in some way. Maybe you are a neuroscientist trying to figure out how songbirds learn their song, or why mice emit ultrasonic calls. Or maybe you're an ecologist studying dialects of finches distributed across Asia, or maybe you are a linguist studying accents in the Caribbean, or a speech pathologist looking for phonetic changes that indicate early onset Alzheimer's disease. crowsetta makes it easier for you to work with your annotations in Python, regardless of the format.It was originally developed for use with the libraries vak and hybrid-vocal-classifier.
Installation#
pip install crowsetta
conda install crowsetta -c conda-forge
Features#
With crowsetta, you can:
work with your annotations in Python, taking advantage of built-in support for many widely used formats such as Audacity label tracks, Praat .TextGrid files, and Raven .txt files.
work with any format by remembering just one class:
annot = crowsetta.Transcriber(format='format').from_file('annotations.ext')no need to remember different functions for different formats
great for interactive analysis and scripts
when needed, use classes that represent the formats to develop software libraries that access annotations through class attributes and methods
convert annotations to widely-used, easy to access file formats (like csv files and json files) that anyone can work with
work with custom annotation formats that are not built in by writing simple classes, leveraging abstractions in crowsetta that can represent a wide array of annotation formats
Built-in support for many widely-used formats
crowsetta has built-in support for many widely used formats such as Audacity label tracks, Praat .TextGrid files, and Raven .txt files.
Here is an example of loading an example Praat .TextGrid file:
import crowsetta
path = crowsetta.example('AVO-maea-basic', return_path=True)
a_textgrid = crowsetta.formats.seq.TextGrid.from_file(path)
print(
f"`a_textgrid` is a {type(a_textgrid)}"
)
print(
"The first five intervals from the interval tier in `a_textgrid`:\n"
f"{a_textgrid.tiers[1].intervals[:5]}"
)
`a_textgrid` is a <class 'crowsetta.formats.seq.textgrid.textgrid.TextGrid'>
The first five intervals from the interval tier in `a_textgrid`:
[Interval(xmin=0.0, xmax=0.051451575248407266, text="'o"), Interval(xmin=0.051451575248407266, xmax=0.6407379583230295, text='Sione'), Interval(xmin=0.6407379583230295, xmax=0.7544662733943284, text='na'), Interval(xmin=0.7544662733943284, xmax=1.244041566788134, text='tosoa'), Interval(xmin=1.244041566788134, xmax=1.3481058803597676, text='le')]
Instead of writing out the class name, each format can also be referred to by a shorthand string name:
import crowsetta
path = crowsetta.example('AVO-maea-basic', return_path=True)
a_textgrid = crowsetta.formats.by_name('textgrid').from_file(path)
print(f"`a_textgrid` is a {type(a_textgrid)} (even when we load it with `formats.by_name`)")
`a_textgrid` is a <class 'crowsetta.formats.seq.textgrid.textgrid.TextGrid'> (even when we load it with `formats.by_name`)
The shorthand string names of built-in format can be listed
by calling crowsetta.formats.as_list():
import crowsetta
crowsetta.formats.as_list()
['aud-bbox',
'aud-seq',
'birdsong-recognition-dataset',
'generic-seq',
'notmat',
'raven',
'simple-seq',
'textgrid',
'timit',
'yarden']
Load annotations from any format, using just one class
To make things even simpler, you only need to remember a single class,
crowsetta.Transcriber, that you can use to work with any format,
given the format’s shorthand string name.
The class also makes it easier to operate on many annotation files all at once.
Here is an example of using crowsetta.Transcriber to load
multiple annotation files.
This class can be used to write succinct scripts for data processing,
or even to write applications that work with multiple annotation formats.
annotation_files = [
'./data/032612/gy6or6_baseline_260312_0810.3440.cbin.not.mat',
'./data/032612/gy6or6_baseline_260312_0810.3442.cbin.not.mat',
'./data/032612/gy6or6_baseline_260312_0811.3453.cbin.not.mat'
]
from crowsetta import Transcriber
scribe = Transcriber(format='notmat')
seqs = [scribe.from_file(annotation_file).to_seq()
for annotation_file in annotation_files]
print(f"Loading {len(seqs)} sequence-like annotations")
print(f"Sequence 1:\n{seqs[0]}")
Loading 3 sequence-like annotations
Sequence 1:
<Sequence with 30 segments>
Write readable code, using classes that represent annotation formats
Although it is convenient to use the Transcriber class,
it can also be helpful to be very clear,
especially when writing code that is read and used by others,
such as libraries developed by a team of research software engineers.
To help make code readable and to make intent explicit,
crowsetta also provides classes for each format.
Here’s an example script written using one of the built-in
annotation formats, to make spectrograms of all the annotated
syllables in a bout of bird song.
Notice that we explicitly access the segments attribute
of a sequence
import librosa
import numpy as np
import crowsetta
# load an example annotation file
path = crowsetta.example('Annotation.xml', return_path=True)
# in the next line we use the class, to make it absolutely clear which format we are working with
birdsongrec = crowsetta.formats.seq.BirdsongRec.from_file(path)
annots = birdsongrec.to_annot() # returns a list of `crowsetta.Annotation`s
syllables_spects = []
for annot in annots:
# get name of the audio file associated with the Sequence
audio_path = annot.notated_path
# then create a spectrogram from that audio file
y, sr = librosa.load(audio_path, sr=None)
D = librosa.stft(y, n_fft=512, hop_length=256, win_length=512)
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)
syllables = []
for segment in annot.seq.segments:
## spectrogram is a 2d numpy array so we index into using onset and offset from segment
syllable = S_db[:, segment.onset_s:segment.offset_s]
syllables.append(syllable)
syllables_spects.append(syllables)
Convert annotations to common file formats like csv files that anyone can work with
crowsetta makes it easier to share data by converting formats to plain text files, such as a csv (comma-separated values) file.
Here is an example of converting a common format to a generic sequence format that can then be saved to a csv file.
import crowsetta
path = crowsetta.example('Annotation.xml', return_path=True)
birdsongrec = crowsetta.formats.by_name('birdsong-recognition-dataset').from_file(path)
annots = birdsongrec.to_annot(samplerate=32000) # returns a list of `crowsetta.Annotation`s
# the 'generic-seq' format can write csv files from `Annotation`s with `Sequence`s.
generic_seq = crowsetta.formats.by_name('generic-seq')(annots=annots)
generic_seq.to_file(annot_path='./data/birdsong-rec.csv')
We load the csv into a pandas DataFrame to inspect the first few lines.
import pandas as pd
df = pd.read_csv("./data/birdsong-rec.csv")
from IPython.display import display
display(df.head(10))
| label | onset_s | offset_s | onset_sample | offset_sample | notated_path | annot_path | sequence | annotation | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1.070 | 1.154 | 34240 | 36928 | /home/docs/checkouts/readthedocs.org/user_buil... | /home/docs/checkouts/readthedocs.org/user_buil... | 0 | 0 |
| 1 | 0 | 1.258 | 1.345 | 40256 | 43040 | /home/docs/checkouts/readthedocs.org/user_buil... | /home/docs/checkouts/readthedocs.org/user_buil... | 0 | 0 |
| 2 | 0 | 1.467 | 1.555 | 46944 | 49760 | /home/docs/checkouts/readthedocs.org/user_buil... | /home/docs/checkouts/readthedocs.org/user_buil... | 0 | 0 |
| 3 | 1 | 1.659 | 1.732 | 53088 | 55424 | /home/docs/checkouts/readthedocs.org/user_buil... | /home/docs/checkouts/readthedocs.org/user_buil... | 0 | 0 |
| 4 | 0 | 1.814 | 1.878 | 58048 | 60096 | /home/docs/checkouts/readthedocs.org/user_buil... | /home/docs/checkouts/readthedocs.org/user_buil... | 0 | 0 |
| 5 | 0 | 1.943 | 2.018 | 62176 | 64576 | /home/docs/checkouts/readthedocs.org/user_buil... | /home/docs/checkouts/readthedocs.org/user_buil... | 0 | 0 |
| 6 | 1 | 2.084 | 2.168 | 66688 | 69376 | /home/docs/checkouts/readthedocs.org/user_buil... | /home/docs/checkouts/readthedocs.org/user_buil... | 0 | 0 |
| 7 | 0 | 2.233 | 2.314 | 71456 | 74048 | /home/docs/checkouts/readthedocs.org/user_buil... | /home/docs/checkouts/readthedocs.org/user_buil... | 0 | 0 |
| 8 | 0 | 2.385 | 2.458 | 76320 | 78656 | /home/docs/checkouts/readthedocs.org/user_buil... | /home/docs/checkouts/readthedocs.org/user_buil... | 0 | 0 |
| 9 | 1 | 2.514 | 2.597 | 80448 | 83104 | /home/docs/checkouts/readthedocs.org/user_buil... | /home/docs/checkouts/readthedocs.org/user_buil... | 0 | 0 |
Now that you have that csv file, you can load it into a pandas DataFrame
or an Excel spreadsheet or an SQLite database, or whatever you want.
You might find this useful in any situation where you want to share audio files of song and some associated annotations, but you don’t want to require the user to install a large application in order to work with those annotation files.
For more detail and examples, please see How to convert any sequence-like format to 'generic-seq'
Write custom classes for formats that are not built in, and then register them
You can even easily tell the Transcriber to use your own in-house format, like so:
import crowsetta
import MyFormatClass
crowsetta.register_format(MyFormatClass)
For more about how that works, please see How to use crowsetta with your own annotation format.
Getting Started#
If you are new to the library, start with Tutorial.
To see an example of using crowsetta to work with your own annotation format, see How to use crowsetta with your own annotation format.
Support#
To report a bug or request a feature (such as a new annotation format),
please use the issue tracker on GitHub:
vocalpy/crowsetta#issues
To ask a question about crowsetta, discuss its development,
or share how you are using it,
please start a new topic on the VocalPy forum
with the crowsetta tag:
https://forum.vocalpy.org/
Contribute#
Issue Tracker: vocalpy/crowsetta#issues
Source Code: vocalpy/crowsetta
License#
The project is licensed under the BSD license.
CHANGELOG#
You can see project history and work in progress in the CHANGELOG.
Citation#
If you use crowsetta, please cite the DOI: